FlexiSLM — Overview
Existing spoken language models (SLMs) typically use a fixed speech-token frame rate (for example, 25 Hz or 12.5 Hz). This fixed-rate design cannot adapt to time-varying speech complexity and does not offer a direct speed-quality trade-off at inference time. We introduce FlexiSLM, the first SLM that supports dynamic and controllable frame rates on both speech input and output. A single trained model can be steered from 12.5 Hz down to 4.0 Hz without retraining.
Key contributions
- Dynamic frame rate SLM framework and validation. We introduce FlexiSLM, the first dynamic frame rate SLM framework, with dynamic frame compression on both speech input and output. Experiments show strong performance at 12.5 Hz and 6.25 Hz, with graceful degradation at 5.0 Hz and 4.0 Hz. We plan to release the code and model to support future research.
- Accurate and practical frame rate control. We propose direct frame rate conditioning, letting users specify the average output frame rate instead of indirectly tuning a merging threshold. This makes FlexiSLM, to our knowledge, the first SLM with frame rate controllability.
- Strong quality-efficiency trade-off. At 6.25 Hz output, FlexiSLM roughly halves AR inference time relative to 12.5 Hz with only minor quality degradation; at high-quality operating points, it outperforms fixed-rate 7B baselines such as Qwen2.5-Omni and Kimi-Audio.
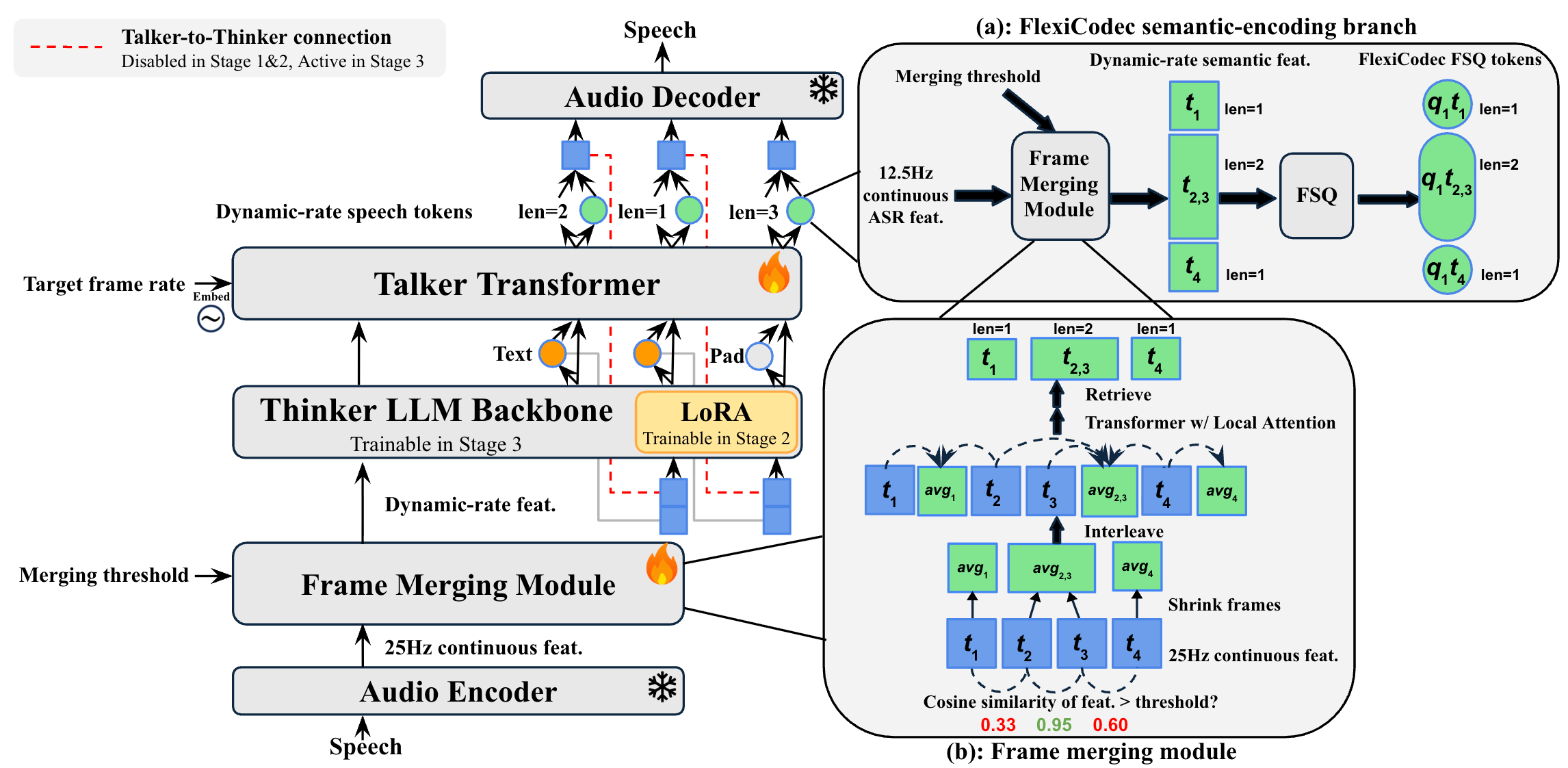
- Talker pre-training. Freeze the LLM backbone and train only the randomly initialized Talker end to end on about 100K hours of English TTS.
- Multi-task LoRA fine-tuning. Activate the input-side Frame Merging Module, Thinker, and Talker; apply LoRA to the Thinker and train on mixed speech tasks.
- Full fine-tuning. Continue from Stage 2, merge the LoRA updates into the LLM, train all parameters, and enable the Talker-to-Thinker connection to improve speech perception and generation quality.
Comparison with Baseline Systems — Speech QA Performance
Each card is one evaluation case. By default we show one sample per dataset; pick a specific dataset in the filter to see all of its samples.
FlexiSLM A → B means A Hz input
and B Hz output frame rates. For example, FlexiSLM 6.25 → 12.5
accepts speech encoded at 6.25 Hz and emits speech tokens at 12.5 Hz.
FlexiSLM-Data Showcase
FlexiSLM-Data is our large-scale speech-to-speech dialogue corpus used to train FlexiSLM. This section presents curated user-assistant speech pairs to give an intuitive view of the data style and interaction quality. Each card shows the user's spoken prompt and the assistant's spoken response, together with transcript text and rough duration / audio-token statistics from the manifest.
The corpus is built with a single-turn construction pipeline:
- Prompt collection. Text prompts are gathered from public QA, instruction-following, and dialogue datasets.
- Response generation. Qwen3-Omni generates text responses. It produces short, conversational, speech-friendly replies.
- Speech synthesis. Responses are synthesized with Qwen3-TTS (fixed speaker “Ryan”), and prompts with Fish-Audio TTS using speakers sampled from English Emilia utterances longer than 5s — yielding 4M samples (30K hours).
- Quality filtering. Format-based filtering removes code, formulas, excessive punctuation, and non-target languages; correctness filtering uses the DeepSeek-V4-Flash API; and ASR-based filtering with Whisper-medium drops samples with WER > 20%.
- Final scale. Filtering yields 1.4M speech-to-speech dialogue samples totaling 9.9K hours.
TTS Demo
This section shows repeat-after-text TTS samples from LibriSpeech prompts. Each card includes the prompt text, the target repeated sentence, and generated audio at five output frame rates (4.0, 5.0, 6.25, 8.0, 12.5 Hz).
Audio Understanding Demo
Seven random samples from the LLaSO-Eval understanding benchmark, with one sample per task. Each card shows the prompt, FlexiSLM text response, ground-truth label, and the source input audio.